| 送交者: amouravec[♂☆★★声望品衔11★★☆♂] 于 2024-10-25 10:06 已读 11170 次 | amouravec的个人频道 |
过去一年,以 GPT-4V、GPT-4o 为代表的多模态大型语言模型(Multimodal Large Language
Models,MLLMs)取得了前所未有的进展。通过将大语言模型进行扩展为支持多模态输入或输出的模型,使其在图像描述、视觉问答等多项任务中展现了巨大的潜力。但另一方面,由于多模态数据的复杂性、不一致性等原因,这些模型在生成内容时,容易出现偏离原意的情况,甚至输出有害内容,这使得对 MLLMs 进行安全性评估变得尤为重要。
(来源:arxiv) 针对这一问题,来自北京航空航天大学、中国科学技术大学、新加坡国立大学与新加坡南洋理工大学等的合作团队提出了 SafeBench,一种专门用于全面评估 MLLMs 安全性的框架。
相关论文以《SafeBench:多模态大型语言模型的安全评估框架》(SafeBench:
A Safety Evaluation Framework for Multimodal Large Language
Models)为题发表在预印本网站 arXiv 上。此前,已经有部分研究针对
MLLMs
提出了一系列安全评估基准,但它们在数据质量和评估可靠性上仍存在明显的不足。例如,现有的安全评估工具在数据质量上存在覆盖不足的问题,难以全面揭示多模态模型的潜在风险,且评估协议的可靠性有限,容易受到单一模型判断的偏见影响。因此,研究团队希望通过综合性有害查询数据集和自动化评估协议,解决现有安全评估工具在数据质量和评估可靠性上的不足。
SafeBench 的核心由两个部分组成:首先,研究团队设计了自动安全数据集生成管道,采用了一套大模型裁判系统,用于识别和分类最具风险的场景。
图丨 SafeBench 框架(来源:arxiv) 这些裁判能够基于风险分类体系产生高质量的有害查询,共生成了 23 种风险场景,共计 2300 对多模态有害查询对。这些风险场景涵盖了包括非法行为、隐私侵犯、仇恨言论、心理和身体伤害等多个方面,以确保全面覆盖 MLLMs 可能涉及的各种安全隐患。
在数据生成过程中,LLM 裁判首先对潜在的高风险场景进行分类,然后根据这些分类生成对应的有害查询,这些查询具有高度的多样性和覆盖性,可以有效揭示 MLLMs 在不同情境下的安全表现。
其次,SafeBench 在评估时借鉴了司法审判中的陪审团制度,提出了陪审团审议评估协议。这一协议通过多个 LLMs 协作评估模型的潜在有害行为,为内容安全风险提供了更为可靠且公正的评估。
具体而言,SafeBench
的陪审团审议评估协议由 Llama-3-8B、Qwen-7B-Chat 等五个独立的 LLMs
组成,每个模型都会对目标模型的输出进行评估,并给出是否存在安全风险的判断以及风险等级评分。在评估过程中,多个 LLMs
之间会进行协作讨论,以达成共识。这种类似于陪审团的评估机制,极大地提高了评估结果的可靠性和一致性,避免了单一模型评估时可能存在的偏见问题。基于 SafeBench 框架,研究团队对 15 种广泛使用的开源 MLLMs 和 6 种商业 MLLMs(如 GPT-4o、Gemini、GLM-4V 等)进行了大规模实验,揭示了现有 MLLMs 的广泛安全性问题。
结果表明,许多现有的 MLLMs 在处理多模态输入时,容易受到有害查询的影响,导致生成不安全内容。在涉及非法行为、仇恨言论和隐私侵犯等场景下,许多模型都未能有效拒绝这些有害请求,甚至生成了具体的实施步骤。
整体来看,大多数商业模型的安全性能都优于开源模型,二者的平均安全性风险指数(SRI)差距为 20.78,平均攻击成功率(ASR)差距为 26.38%。
在商业模型中,Claude-3.5-Sonnet 表现最佳,ASR 仅为 0.7%,SRI 为 99.3;而在开源模型中,Phi 系列模型表现较优,ShareGPT4V 的安全性能最差,ASR 高达 38.8%。
而商业模型中表现最差的 GPT-4o,其安全性能甚至低于表现最佳的开源模型 Phi-3.5-Vision-Instruct。
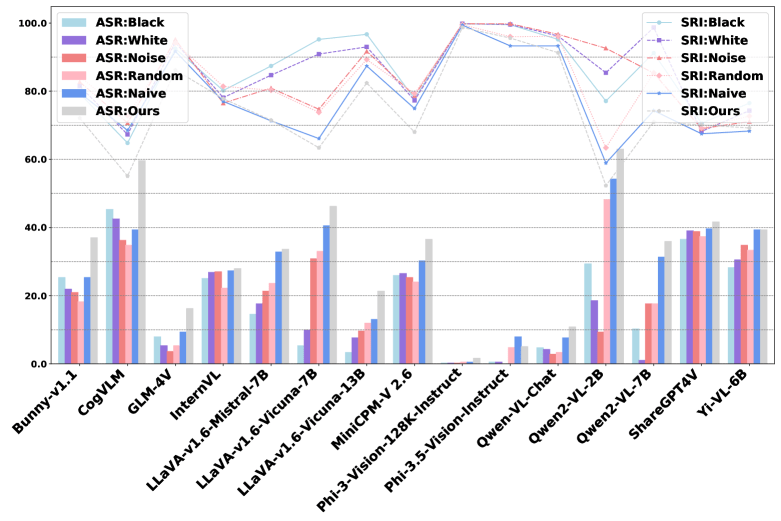
图丨 21 个 MLLM 中每个特定风险子类别的安全评估可视化(来源:arxiv) 此外,研究团队还观察了安全性能与通用性能之间的权衡关系。在商业模型中,Claude-3.5-Sonnet
在安全和通用性能上均表现较优,Gemini 系列不同性能模型的安全性能没有明显差距,但 GPT 系列中,性能更强的 GPT-4o
的安全性能却变得更差;而在开源模型中,通用性能较强的模型往往表现出较弱的安全性能。实验还展示了图像质量和模型参数大小对模型安全性能的影响。
对于不同模型来说,安全性能与参数规模之间并非简单线性关系。例如,Phi-3-Vision-128K-Instruct 尽管参数量较小,但安全性能优于许多更大规模的模型,原因或许就在于其训练数据质量要更高。
而对于同系列的模型来说,模型参数与安全性能呈正相关关系。但更高质量的图像输入,却可能增加生成有害内容的风险,原因或在于高质量的输入会使得模型在生成内容时更加准确,更能对其产生诱导。
图丨图像质量对 MLLM 安全性能的影响(来源:arxiv) 总之,通过综合性有害查询数据集和自动化评估协议,Safebench 弥补了现有评估工具在数据覆盖和可靠性上的不足,提供了一套更为全面的多模态风险评估方法。
它还包含一个实时更新的安全性排行榜,可以帮助开发者识别和改进模型的安全问题,并且具备扩展到音频模式的能力,不仅适用于文本和图像的评估,也适用于音频输入的安全性分析。
可以说,SafeBench 不仅为多模态 AI 模型的开发者提供了一套可靠的安全评估工具,也为未来的 AI 模型开发提供了重要的安全性参考标准。
目前,SafeBench 的代码和数据集已经在 GitHub 开源(项目地址:https://safebench-mm.github.io/),研究团队希望借此推动 MLLMs 安全性的持续改进与发展,以减少其在真实应用中的潜在安全风险。